2009-09-13
*1252813676*iPhoneでフォトアルバムに画像を保存する方法
||
void UIImageWriteToSavedPhotosAlbum (
UIImage *image,
id completionTarget,
SEL completionSelector,
void *contextInfo
);
||
第2引数以降は画像の保存が終わったあとにコールバックさせるためのものなので必要なければ全部nilにしていい。
今まで保存機能がないせいでスクリーンショットしてて枠が出ていたけど、ちゃんときれいに保存できるようになった。
f:id:nishiohirokazu:20090913125809j:image
*1252821508*PRML(パターン認識と機械学習) Hackathon 飛び入り日記
hr
すばらしい発見をしたような気になる→冷静になる→アレ?(今ここ)
hr
5分ではやはり語りきれなかったのでここで。
これによってこのニューラルネットはパターンAっぽい入力を受けたあとには「Bが来そうだな」と予想できるようになる。パターンAが来たあとにノイズっぽいどこにも分類されない入力が来た時にはボルツマンマシン部分の「次はBが来るぞ」信号でパターンBが発火して「本当はノイズだったんだけどBが来たものと認識される」っていうとても人間っぽい挙動をする。そして入力からの刺激をなくしてやるとボルツマンマシンの「次は何が来る」情報だけでニューラルネットの状態が更新されて行って「夢を見ている」ような状態になる。
さて、ここまでで「ある入力が来た時に、次にどんな入力が来そうか予測」ができるようになった。しかし、これではAを見た時に「次はB」、Bを見た時に「次はA」という予測はできても「AとBの間を遷移し合うパターンXが存在する」という理解にはならない。なのでここで夢見のフェーズが重要で、夢を見ている間に適当なランダム発火からしばらく連想を走らせると、AとBの交互に移り合う遷移などのところに落ち着くので、すこし時系列にぼかして認識すると「AニューロンとBニューロンが光っているパターン」という空間的パターンに変化する。時系列パターンが空間的パターンに変化したところが重要で、これをまたSOMに食わせることでパターンのシンボル化ができるわけだ。ひとたびパターンのシンボル化ができてしまえばそのシンボルの間の遷移でより高度な抽象化ができる。
hr
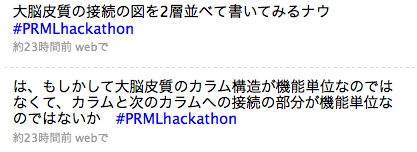
僕の大脳皮質に関する理解を確認しつつ、割といろいろなところにいろいろな種類の細胞があるから現時点でわかっている配線だけにこだわらなくても良さそうだという感触を得る。で、大脳皮質の図を描いた。第4層(以下x4)に入力が入ってきた時に、x2とx3が刺激され、その信号は上位レイヤーの第4層(以下y4)に届く。その過程でy5も刺激する。一方逆向きの流れもあって、y5からはy6を介して下のレイヤーに信号が送られる。送られてきた信号は軸索がたくさん集まっているx1を通ってたくさんのx2, x3, x5に送られ、またx2, x3からはx5, x6に信号が送られる。 (あとで図を入れる)
見ていたんだけども大脳皮質の1レイヤーだけ見ていてもリカレントネットワークを形成できそうに見えない。うーむ。
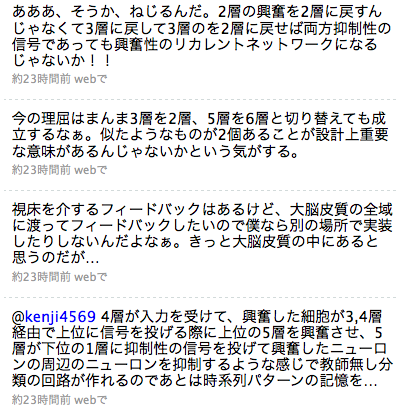
大脳皮質間の結合(corticocortical connectionという表現でOK?)が機能単位だという過程で考える。第4層(以下x4)に入力が入ってきた時に、x2とx3が励起されるわけだけど、この例えばx2の興奮は上位の第4層(以下y4)に伝えられる過程でy5、y6を伝って降りてきてx1の軸索がたくさん集まっているところを通って抑制性の刺激を与えることができる。軸索がたくさん集まっているということはそこで広い範囲に信号の伝達ができるということで、自己組織化マップの「最も強く発火しているニューロンが他のニューロンの活動を抑制する」ってのができそうだ。やった。あとはボルツマンマシン的なものが残りのスペースに収まるかどうか。 おお、そうか、なんで2層と3層の使い分けがよくわからないのに2つあるのかと思ったらそういうことか。片方が自己組織化マップで片方がボルツマンマシンなんだ。このTwitterでの発言は適切ではないので修正すると、
第4層(以下x4)に入力が入ってきた時に、x2とx3が励起され、x2の興奮は上位の第4層(以下y4)に伝えられる過程でy5、y6を伝って降りてきてx1の軸索がたくさん集まっているところを通ってx3に抑制性の信号を与えることができる。このとき、自分自身を抑制するんじゃなくて周辺のニューロンの抑制をする(側抑制)、「AとかBとかCって可能性も考えられるけど、一番強いのはAだからAってことにしよう」というわけ。x3はx4からの入力と抑制信号とでx2よりも「よくマッチしているニューロンだけ厳選で発火したパターン」になる。x3の発火はまたy4に送られる過程で降りてきてx2に繋がる。ここは弱く興奮性。この信号だけで大勢が決するほどではない。でここが学習をすることで「入力から考えるとCかDなんだけど、さっきAだったんだから次はBかCだと思うな」という肯定的な絞り込みがかかって、で、これがまたx3に行くところで「BとかDとかCが考えられるけど、まあ一番強いのはCだな」って感じになる。 という結論に到達したところでタイムアップだったので自己紹介もかねて5分で説明しようとしたが無理だった←いまここ
あ、あと今思いついたんだけど視覚野の細胞の応答速度ってどの程度だろう。仮に25msecとすると数字で見ると小さそうだけど、Hzでいうとたかだか40Hzなのでサッケードで50Hzくらいで眼球が動いているとすると常時モーションブラーだよねぇ。
*1252850497*のぐち
f:id:nishiohirokazu:20090913230124j:image
のぐちはみておるぞ!
f:id:nishiohirokazu:20090913230207j:image
きつねめの、のぐち
f:id:nishiohirokazu:20090913230302j:image
こまっっちゃたのぐち~
f:id:nishiohirokazu:20090913230336j:image
3の倍数の時に馬鹿になるのぐち
{kind=link}
{kind=link}