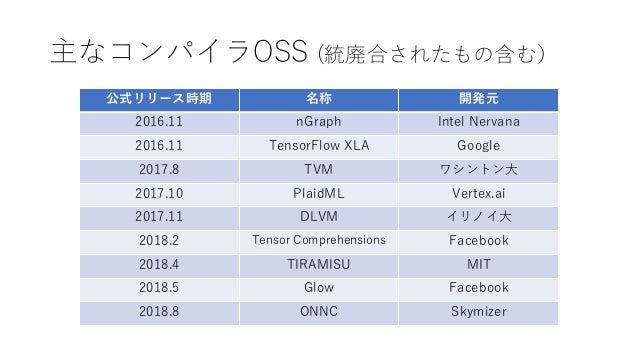
DNNコンパイラ
学習済みモデルを最適化し、様々なハードウェア向けにコード生成をする
推論用の最適化コードを出力
機械学習モデル→機械学習演算に特化したハードウェアの最適な実行コード、に変換
何が嬉しいか
2段階の最適化
②primitiveな演算セットレベルでの最適化
↑ターゲットとなるハードウェアの特性を活かしたもの
新しく出てくるハードに対応しやすい
モデルサイズは小さくなるの?mrsekut.icon
https://image.slidesharecdn.com/tvmintro-181108053329/95/tvm-3-638.jpg
例
① High Level Optimizer(HLO)
② Low Level Optimizer(LLO)
①
②
① GraphOptimizer
② IROptimizer
参考
{kind=link}