PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Optimization
Motivation 選んだ理由
プロンプト生成に興味あり
従来のAPE に対して10%弱の向上幅
探索手法が賢い
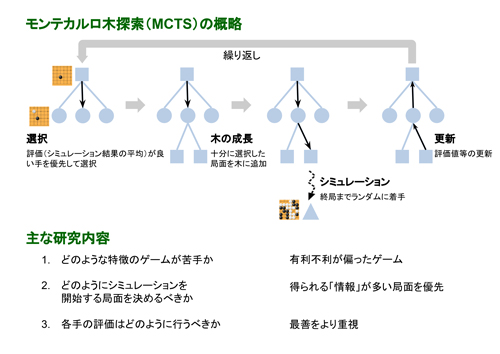
MCTS (モンテカルロ木探索)がベースになっている
囲碁では盤面評価のためNN以前から現在まで用いられている。手をランダムに打つので高速で、囲碁のように盤面の変化が一方通行なゲームで特に有効。将棋だとランダムはかなり難しく非効率なのでNNなどの盤面評価と組み合わせて利用する。
主張が強め
"我々は、専門家が手作業で作成したプロンプトと同等の品質のプロンプトを自律的に作成する最適化手法であるPromptAgentを提案する。"
Summary どんなもの?
プロンプト最適化手法: PromptAgent
初期プロンプト $ \cal{P}_0 と、訓練事例(input/output) $ \{q_i, a_i\}^N からスタート
訓練事例での評価が最も高いプロンプトを探す
$ {\cal P}^* = \argmax_{\cal P \in S} \sum_i {\cal R}\left(p_{\cal B}\left(a_i | q_i, {\cal P}\right)\right)
評価関数 $ \cal{R} :正解率など
$ \cal S はすべてのプロンプト空間(無限にある)
細かい数式はたくさん出てくるが、図のイメージが伝われば大体OK
https://gyazo.com/02e0fb03468572bef556c0e5330a6490
MCTSの文法に合わせているが、$ s_t = {\cal P}_tのこと
$ a_tはプロンプト改良の1ステップを表す。ステップの中身は次の3つ
事例の入力に対してプロンプトを使い回答を生成
回答中にあるエラーの原因をLLMでフィードバックとして生成
フィードバックを元に、プロンプトを更新
$ r_t は報酬関数
Contribution 先行研究と比べてどこがすごい?
APEに対してGPT-3.5で9.1%、GPT-4で7.7%、PaLM 2で6%向上、人手のプロンプトに対しても一貫して向上している
MCTSを使うことで探索のコストをある程度勘案にいれた探索ができている
従来の手法は、最善のプロンプトにたどり着く保証がない
今回の手法は、実際のところ状態集合や行動集合が有限と仮定すると、十分な試行回数があれば最善のプロンプトを返すことが保証されている。
Method 技術や手法のキモはどこ?
プロンプト空間を効率的に探索するため、強化学習でよく使われる Markov Decision Process (MDP) としてプロンプトの改良を定式化する
MPD = $ ({\cal S}, {\cal A}, T, r)
$ \cal S は状態集合(プロンプト空間)
$ \cal Aは行動集合
$ Tは遷移関数: $ T: {\cal S \times A \rightarrow S}
$ r は報酬関数 $ r: {\cal S \times A} \rightarrow {\mathbb R}
これをMCTS (Monte Carlo Tree Search) を使って探索
状態・行動価値関数 Q: $ \cal S \times A \rightarrow \mathbb R を定義。潜在的な未来の報酬(その先の枝の有効性、囲碁でいう盤面評価)を表す
MCTSは4つのステップからなる。以下のステップを一定の試行回数試した時点で終了。
選択 (UCT: Upper Confidence bounds applied to Trees, UCBのTree版)
$ a_t^* = \argmax_{a'_t \in A(s_t)} \Bigg( Q(s_t, a'_t) + c \cdot \sqrt{\frac{\ln {\cal N}(s_t)}{{\cal N}(ch(s_t, a'_t))}} \Bigg)
$ cは定数
$ {\cal N(s_t)} は状態 $ s_tを訪れた回数
この式を使う前に1回は試す必要がある
$ ch(s,a)は$ s_tで$ a'_tを選んだ時に行く先の状態(子ノード)
よく探索済みのところは未探索度合いを表している
展開: 選択したノードに複数の子ノードを追加する
図3(b)のステップ1-ステップ3 を実行
理論的には無限に存在しうるが、限られた事例でLLMが提案する修正案は有限のものに落ち着く様子
シミュレーション:追加した子ノードからスタートして、greedy に子ノード、孫ノードの探索を繰り返す。終端(深さ制限、early-stop 基準)に到達した時点で終了
各ノードごとにStep1-Step3 を実行し、その中で一番スコアの高い行動を選択、深さ優先の探索を行う
バックプロパゲーション:シミュレーションで終端に達したとき、終端ノードからルート(初期プロンプト)までの経路に沿って、報酬を伝播させ、Q関数を更新する。
$ Q^*(s_t, a_t) = \frac{1}{M}\sum^M_{j = 1}\Bigg( \sum_{S'\in S^j_{s_t}, a' \in A^j_{a_t}} r(s',a') \Bigg)
M は$ (s_t, a_t) から先の探索済みパスの数
ノード $ (s_t, a_t)から始まる探索済みパスの報酬の平均を表している。
終了後、最も高い報酬を得られたベストパス中のベストノードを選択する
Experiments どうやって有効だと検証した?
BIG-Bench Hard (BBH): 特定ドメインでの一般的なNLPタスク
https://gyazo.com/ca669be8620819ac59ad1d32742930db
例: Penguins
Here is a table where the first line is a header and each subsequent line is a penguin: name, age, height (cm), weight (kg) Louis, 7, 50, 11 Bernard, 5, 80, 13 Vincent, 9, 60, 11 Gwen, 8, 70, 15 For example: the age of Louis is 7, the weight of Gwen is 15 kg, the height of Bernard is 80 cm. We now add a penguin to the table: James, 12, 90, 12. And here is a similar table, but listing giraffes: name, age, height (cm), weight (kg). Jody, 5, 430, 620\nGladys, 10, 420, 590. Marian, 2, 310, 410\nDonna, 9, 440, 650
Which is the oldest penguin?
Options: (A) Louis (B) Bernard (C) Vincent (D) Gwen (E) James
Biomedical NLU 生命科学分野での自然言語理解
https://gyazo.com/458b424735645b0cbaa36fea7221a6ad
NCBI 論文から病名を抽出
Biosses 文類似度
Med QA 医療QA
GPT-3.5 で探索したプロンプトがGPT-4, PaLM2で利用できるかの検証
https://gyazo.com/88bea8893c21c1d90d0128537d2bdbb8
作成されたプロンプトの質的評価
https://gyazo.com/96965060cbc4620452be701a67518953
タスク説明、例外処理、解き方の指示、フォーマットなど人が作るプロンプトと同じような役割をもつ文が含まれている
この例だと優先順位や、用語定義などは含まれていない
探索の効率についての分析
https://gyazo.com/360eee32efe8d83aab2a56a5d37a703f
Greedy な探索やAPEに比べて探索回数を押さえつつ、高い精度が出せている
探索の深さも3〜4で十分そう
ステップごとに改良されるプロンプトの例
https://gyazo.com/e3bba10b8418b974aeb18ded27c5ff22
エラーからのフィードバックで徐々に指示が追加されて行っている様子がわかる
Discussion 議論はある?
実際には、プロンプト空間も行動空間も無限にあるため、MCTSが最善なのか?
Greedy や Beam と比べた時の比較が付録にある
遺伝的アルゴリズムとは比べていない
プロンプト自体の探索とは別に、同じプロンプトから出発して回答の探索をツリーで行う研究もあるので、プロンプトの探索と回答の探索の使い分けはどうすればよいのか
かなりの量の訓練データ(60-200件)を必要とする所が実用上は厳しめ
{kind=link}